DeepSeek正式发布全新多模态模型DeepSeek-OCR
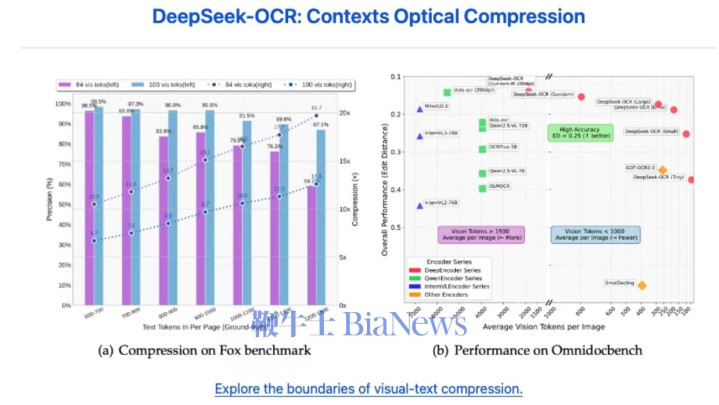
这款模型以“探索视觉-文本压缩边界”为核心目标,从大语言模型(LLM)视角重新定义视觉编码器的功能定位,为文档识别、图像转文本等高频场景提供了兼顾精度与效率的全新解决方案,引发技术领域与行业应用端的广泛关注。
DeepSeek-OCR采用分层设计的视觉编码方案,支持Tiny、Small、Base、Large、Gundam五种尺寸配置,可根据不同硬件条件与场景需求灵活选择。
其中Gundam版本特别针对大尺寸复杂文档优化,采用1024×640混合尺寸配置及专属裁剪模式,能更精准处理多栏排版、图文混杂的专业文档。
值得关注的是,模型创新性融合了SAM(SegmentAnythingModel)的图像分割能力与CLIP的视觉理解能力,并通过MlpProjector模块实现与语言模型的高效对接,这一设计不仅让模型能精准提取文本内容,还能同步捕捉文字、表格、图像在原图中的空间布局信息,为后续结构化输出提供关键支撑,解决了传统OCR“只认文字、不识布局”的痛点。
在实际功能层面,DeepSeek-OCR展现出极强的多场景适应性:
既支持单张图像、PDF文档的单次处理,也能应对批量图像的高效识别,且所有输出结果均支持Markdown格式,方便用户直接编辑或导入其他办公软件;
同时,模型内置边界框检测功能,可精准定位文本块、表格、插图在原图中的位置,结合动态裁剪策略,能根据图像尺寸自动调整处理逻辑,在保证识别精度的同时大幅提升处理速度。
此外,模型还集成vllm框架实现高效推理,支持多任务并发处理,即便面对大规模文档处理需求,也能保持稳定的响应效率,尤其适合学术论文、企业报表、个人简历等复杂文档的数字化转化场景。
为降低开发者与企业用户的使用门槛,DeepSeek-OCR提供了全链路的工具链支持:
模型已完整开源至HuggingFaceHub,用户可直接通过transformers库加载使用;官方同步发布了详细的参数配置指南,明确不同硬件环境下的最优模型规格选择建议;
同时配套开发了PDF转图像、批量处理脚本、结果可视化工具等辅助功能,即便是非专业技术人员也能快速上手。
从示例代码来看,仅需数行代码即可完成从模型加载到结果输出的全流程,例如通过调用AutoModel与AutoTokenizer接口,输入图像文件与“转换文档为Markdown”的提示词,就能快速得到结构化文本结果,极大简化了应用开发流程,且模型支持零样本推理,无需额外微调即可应对多数通用文档场景。
据DeepSeekAI团队介绍,DeepSeek-OCR于2025年正式对外发布。
目前,感兴趣的开发者可通过DeepSeek-OCR的GitHub仓库获取详细信息,或加入官方Discord社区参与技术讨论,随着后续迭代优化,这款模型有望在文档智能处理领域拓展出更广阔的应用空间。(转自AI普瑞斯)